The problem
Relational storage is safe, and widely understood. Domain-driven design (DDD) and event stores are new and not so widely understood. Applying DDD to your project can have dramatic architectural impact, meaning the cost of making a mistake can be very high. Given the lack of sufficient expertise among most teams, this is a significant project risk.
In the DDD world, purists will say that aggregate (root) objects should be saved in an "event store". This means that the latest state of the object is reconstructed by sequentially re-applying all past events since the beginning of time (or since the last checkpoint). This approach implies a couple of major architectural decisions at the start of your project:
- The scope of the aggregate root must be defined (along with the transaction scope) so that the event store contains only significant events and no other. Otherwise, reconstructing the state based on events becomes cumbersome. The consequence: if you make a mistake here, you are facing architectural redesign afterwards - not a pleasant outlook. Yet, few people have good knowledge of DDD at this time and agile practices almost forbid a design-up-front approach.
- The storage itself must be chosen - possible a non-relational database or even flat files of your own. Again, this is a major decision in your project and it may or may not be compatible with the evolution of your requirements.
- Querying a non-relational database has its challenges and limitations. This means you would have to program query logic yourself.
To summarise: the decision to take a DDD purist approach is a significant one, and the cost of making a mistake is very high. By definition, in the beginning of our project we do not know everything yet so we would prefer to be more flexible - i.e. not favouring one approach over the other and staying compatible with future requirements. This strategy also allows us to mitigate the risks due to lack of expertise with DDD in the project teams.
The solution
Architecture Diagram
Let's suppose your application is about order management. Our proposed architecture looks like this:
Error: image not found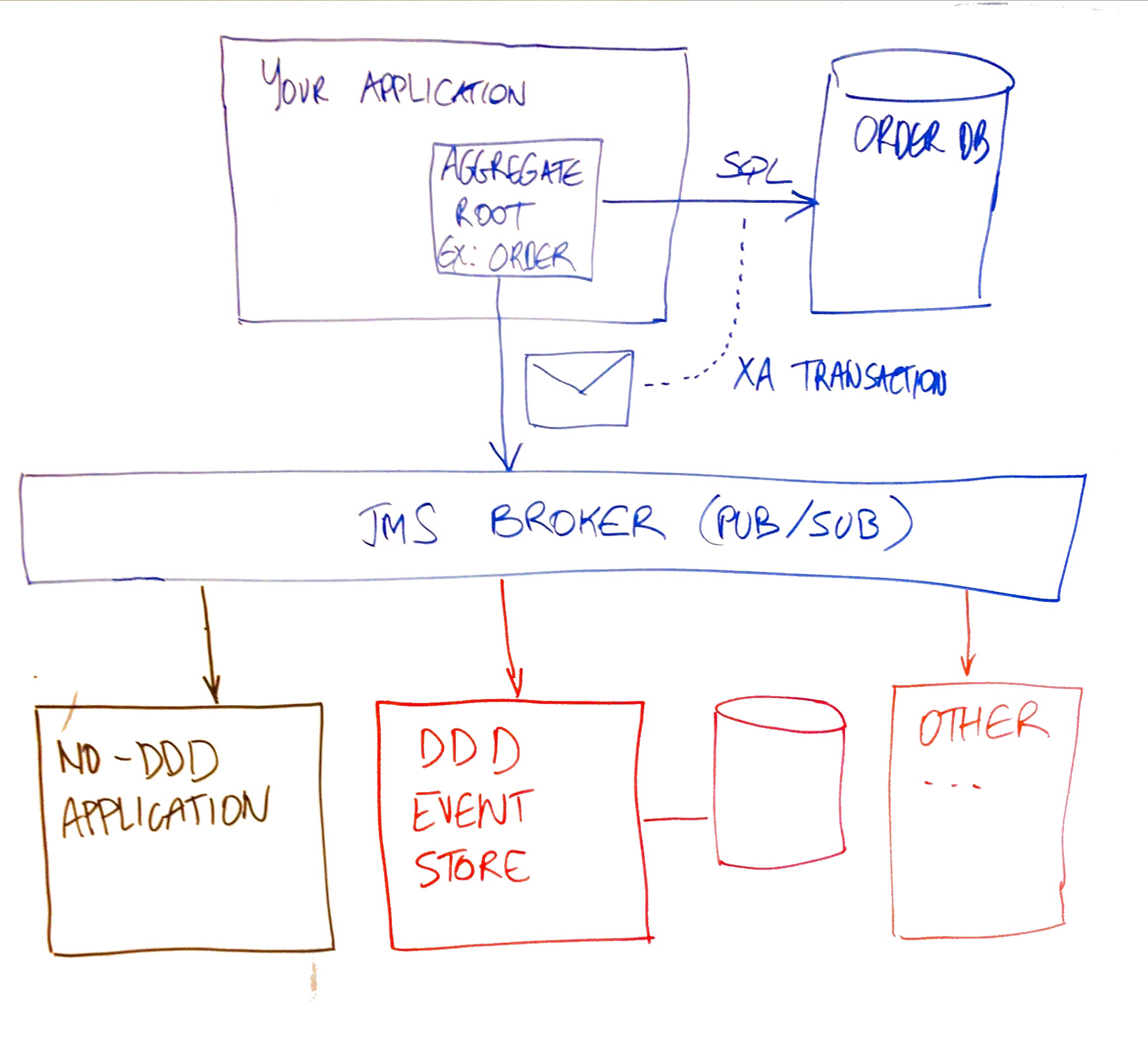{kind=link}
Use both relational and DDD event storage together. Have your developers program in what they know and like best and combine the two approaches seamlessly in a loosely-coupled way, as explained below.
Persist your domain objects the traditional way, produce domain events as publish/subscribe
- Just like you always did: use Hiberate, JPA or JDBC (or any other relational persistence mapping) to store your objects in the database.
- Within the same transaction, publish a domain event on a JMS/XA destination.
- Use ACID transactions (like with Atomikos) to make both of the above happen together exactly once - or not at all.
This is shown in the architecture diagram: the Order management application stores orders in the relational database and posts an event message to the broker.
Add any number of event subscribers and/or event stores
The way events are produced above allows any number of subscribers to treat every single event, thereby storing it, transforming it into a specific query model or anything else for that matter. This allows you to build your event store side-by-side with the traditional application architecture, so you don't have to make any significant high-risk decision early on in your project. Your other applications can choose to either query the traditional database, or use the event store one way or another. The point is: they don't have to make a choice right now.
The architecture diagram shows how this can work for a No-DDD application, an event store and any other application besides those.
Additional benefits
Compatibility with non-DDD consumers / applications
While it may be feasible for your teams to make the internal design choice to go for DDD, there will always be external or 3rd party applications that need to integrate with your work and that were built without the DDD mindset. In other words: not all applications were designed for querying an event store to retrieve the latest events. For these applications, the publish/subscribe approach offers a flexible and proven way of integrating with your projects.
Orders are saved faster
Implementing an event store can be a challenge, and it typically takes a lot of event records to store the latest state. Storing a new order can also take a lot of inserts, which are slower than relational updates.
Easy queries on the relational store
Querying an event store is not straightforward. Because the relational storage is conserved, SQL can come to the rescue.
Want to try for yourself? Download and start using TransactionsEssentials today - it's FREE!
The XA transactions in this post are easily provided with our free product - try it out for yourself by giving your email address and we'll send you the download instructions plus documentation:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Add a comment